[Paper Review] VAE: Auto-Encoding Variational Bayes
![[Paper Review] VAE: Auto-Encoding Variational Bayes](/content/images/size/w1200/2024/07/VAE.webp)
Generative Model계의 논문의 시초가 되는 VAE를 알아보자.
해당 논문은 위의 arXiv에서 찾을 수 있다.
해당 포스트는 아래의 글들을 참고했다.



 kyujinpy
kyujinpy rahites
rahites
 치킨고양이짱아
치킨고양이짱아



0. Basic Knowledge
MLE는 어떠한 상황이 주어졌을 때 해당 상황을 가장 높은 확률로 산출하는 후보를 선택하는 방법을 뜻한다 (주어진 데이터셋이 나올 확률을 최대로).
예를 들어 땅에 떨어진 머리카락을 발견했을 때 이것이 남자의 머리카락인지 여자의 머리카락인지 판단하는 Task가 있다고 해보자.
이 때 우리는 성별별 머리카락 길이의 일반적인 확률분포를 떨어진 머리카락의 길이와 비교하여 성별을 판단하는 추론을 진행할 수 있다.
다만, MLE에는 치명적인 단점이 있는데, 일반적인 경우에 발생하는 추론은 Posterior(사후) Distribution이 존재하지 않는 경우가 많다는 점이다. 예를 들어, "머리카락 길이별 그것이 남자일 것일 확률 분포"는 보통의 경우에 존재하지 않는다. 이를 해결하기 위해 MAP를 도입한다.
MLE가 likelihood를 최대화 시키는 방법이라면, MAP은 Posterior를 최대화 시키는 방법이다. 일반적인 추론 상황에서는 Posterior이 존재하지 않기 때문에 Bayes' Rule을 이용한 추론을 진행한다.
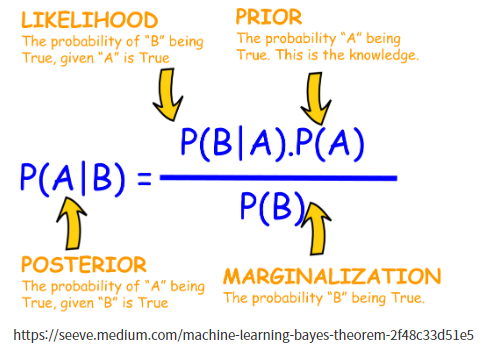
$$ P(A|B) = \frac{P(B|A)P(A)}{P(B)}$$
- $\text{A}$: 구하려는 대상
- $\text{B}$: 주어진 대상 (관측 값)
- Prior $P(A)$: 구하려는 대상 자체의 확률
- Likelihood $P(B|A)$: 구하려는 대상이 주어졌을 때, 해당 관측값이 나올 확률
- Posterior $P(A|B)$: 관측값이 주어졌을 때, 구하려는 대상이 나올 확률
Ex.1 머리카락의 길이를 보고 성별을 예측
- 관측값: 머리카락의 길이
- 구하려는 대상: 성별 (Male/Female)
- Posterior: P(성별|머리카락)
- Likelihood: P(머리카락|성별)
- Prior: P(성별)
$$P(\text{성별}|\text{머리카락}) = \frac {P(\text{머리카락}|\text{성별})P(\text{성별})} {P(\text{머리카락})}$$
해당 문제를 풀 때, Likelihood를 최대화하는 MLE방식은 $P(\text{머리카락}|\text{남자})$와 $P(\text{머리카락}|\text{여자})$ 중 더 큰 Likelihood 값을 선택한다.
반대로 MAP 방식은 두 Posterior를 비교해서 둘 중 더 큰 값을 선택하는데, 처음부터 Posterior를 알기 어렵기 때문에 Bayes' Rule을 사용하여 계산한다. 다만 Prior를 구하는 것이 어렵기 때문에 현실에서는 MLE를 사용할 때도 많다.
Ex.2 영상에서 피부색을 검출하는 문제
영상에서 피부색을 검출하는 문제는 각 pixel 별로 피부색에 해당하는지 아닌지 여부를 결정하는 분류 문제로 볼 수 있다.
다만, 이때 MAP 방식을 사용한다면 Posterior $P(\text{피부색}|pixel)$을 Bayes' Rule에 의해 구하는 데 있어서 Prior $P(\text{피부색})$이 필요한데,
우리가 수집한 데이터 만으로는 세상에 있는 피부색 확률이라 추정할 수 없다.
따라서 위의 경우에는 MAP보다는 MLE 방식을 사용해야 한다.
2. Method
VAE 논문의 기본적인 Flow는 다음과 같다:
1) 생성 모델을 이용하여 기존 Training Data와 비슷한 이미지를 생성하기 위해, 실제 확률분포 $p^{*}(x)$로 근사할 확률분포 $p_{\theta}(x)$를 구한다.
2) 하지만 Model Parameter와 이미지간의 관계를 직접적으로 학습하기에는 너무 복잡하므로, 중간 단계인 latent variable $z$를 도입하여 latent variable과 이미지간 학습하기 용이하도록 만든다.
Latent Variable $z$
잠재 변수란 관측 가능한 데이터와 관련은 있지만 직접적으로 측정되지 않는 변수를 의미한다.
일반적으로 데이터에서 패턴을 발견하거나 결과를 예측하는 데 사용되며, 잠재 변수를 사용하면 데이터의 차원을 줄일 수 있다.
그럼 Continuous Latent Variable은 무엇일까?
연속 잠재 변수는 잠재 변수의 한 유형으로 연속적인 값을 가지는 변수이다. 실수 범위 내에서 가능한 모든 값을 가질 수 있으며 주로 확률론적 모델링에서 사용된다. (ex. 주성분 분석(PCA), 요인 분석(Factor Analysis), 가우시안 혼합 모델(GMM))
즉 VAE는 Input Image $x$를 잘 설명하는 Feature를 latent vector $z$에 담고, 이 latent vector $z$를 이용하여 $x$와 유사하지만 완전히 새로운 데이터를 생성해내는 것을 목표로 한다.
3) 다만 $p_{\theta}(x)$는 Decoder의 확률분포 $p_{\theta}(x|z)$만으로 구할 수 없기에, 추가적으로 Encoder $q_{\phi}(z|x)$ 를 정의하여 $p_{\theta}(z|x)$로 근사한다.

- $p_{\theta}(x) = \int p_{\theta}(z) p_{\theta}(x|z)dz$ 모든 $z$에 대해 integration을 수행하는 것은 불가능하다.
- $ p_{\theta}(z|x) = \frac {p_{\theta}(x|z)p_{\theta}(z)} { p_{\theta}(x)} $에서 Marginal $p_{\theta}(x)$가 intractable하기에 Posterior $ p_{\theta}(z|x)$를 계산할 수 없다.
$$ p_{\theta}(z|x) = \frac {p_{\theta}(x|z)p_{\theta}(z)} { p_{\theta}(x)} $$
따라서, Encoder $q_{\phi}(z|x)$를 도입하여 $q_{\phi}(z|x) \approx p_{\theta}(z|x)$ 위의 식을 이용해 $p_{\theta}(x)$을 얻고자 한다.
정확히 말하자면 Encoder $ q_{\phi}(z|x^{(i)})$를 도입하는 이유는
Data likelihood $p_{\theta}(x)$의 tractable한 lower bound를 유도하여 optimize할 수 있도록 만들기 위해서이다.
1) ~ 3) 까지는 VAE의 Structure 부분에 대한 설명이다. 이후 4) ~ 7)은 VAE의 목적에 따른 Training, Optimization 방법에 대한 설명이다.
VAE의 목적은 Model을 통해 생성한 이미지가 학습에 사용한 이미지 데이터셋에 대해 가지는 유사도를 가장 높일 수 있는 파라미터 $\theta^*, \phi^*$ 를 찾는 것이다.
Model Parameter $\theta$가 주어졌을 때, 우리가 원하는 정답인 $x$가 나올 확률이 가장 높기를 원한다.
$p_{\theta}(x)$가 높을수록 좋은 모델이다.

따라서, $\log p_{\theta}(x^{(i)})$를 Maximize 시키는 최적의 Parameter를 찾는 optimization 과정이 어떻게 이루어지는지 살펴보자.
4) $\log p_{\theta}(x^{(i)})$를 Maximize 시키는 Decoder, Encoder Parameter $\theta^*, \phi^*$를 찾는다.
5) $\log p_{\theta}(x^{(i)})$를 Maximize 하기 위해 Lower Bound인 ELBO를 간접적으로 Maxmize 시킨다 . ( $ - \mathcal{L}(x^{(i)}, \theta, \phi)$를 최소화 시킨다)

6) $\arg \min_{\theta,\phi} \sum_i -\mathbb{E}_{q_\phi(z|x_i)}[\log(p(x_i|g_\theta(z)))] + D_{KL}(q_\phi(z|x_i)||p(z))$ 와 같이 2개의 항인 Reconstruction Error, Regularization Term으로 각각 분리해서 학습한다.
7) Regularization Term은 KLD를 통해 식을 전개하고, Reconstruction Error는 Decoder의 Distribution이 Bernoulli/Gaussian에 따라 식을 전개한다.
2.0) Method Basics
생성 모델은 주어진 데이터 셋과 유사하면서 새로운 데이터를 생성해 낼 수 있는 모델을 만드는 것이 목표이다.
이를 위해 확률적인 관점에서 보면 $x$라는 데이터 셋이 있을 때 $x$가 sampling된 확률분포 $p^*$를 알아내는 것이 목적이다.
이때, "애초에 확률분포 $p^*$ 자체를 모르는데 $x$가 Sampling 되었는지 어떻게 알 수 있는가"라는 의문이 들 수 있다.
당연히 실제 확률분포 $p^*$를 모르기에, $x$가 해당 확률분포에서 Sampling 되었다고 가정하는 것이다.
하지만 현실적으로 우리가 직접적인 확률분포 $p^*$를 알아내는 것은 불가능하다.
따라서 우리는 Real Distribution인 $p^*$과 비슷하면서 새로운 데이터를 만들 수 있는 확률분포 $p_\theta$를 만들어 근사시킨다.
$$ p^{*}(x) \approx p_{\theta}(x)$$
그렇지만 아직도 $p_{\theta}(x)$를 직접적으로 알아내는 것은 Intractable하다. 따라서 VAE 모델은 몇 가지 가정 하에 생성모델을 설계하고 훈련하여 $p_{\theta}(x)$를 간접적으로 알아내는 것을 가능하게한다.
Two Assumptions
[가정 1]
i.i.d 가정(independent and identical distribution assumption)
우리가 만들고자 하는 데이터의 전체 집합을 $X$라고 할 때,
$X$의 각 원소들을 $p_{\theta}(x)$에 의해 확률적으로 뽑는다면 각 시행은 독립적이며 동일한 분포를 가진다.
(여기서 $X$는 주어진 데이터만이 아닌 주어진 데이터 분야의 모든 데이터를 말한다)
- Independent : 생성모델로 어떤 이미지를 새롭게 만들 때, 이전 혹은 이후에 생성할 이미지에 영향 X
- Identical : 이미지 각각은 해당 데이터 집합 $X$에 대한 이미지로, 뜬금없이 다른 $Y, Z$에 대한 이미지를 만들어내지 않음
[가정 2]
충분한 양의 학습 데이터 셋 $\{x^{(i)}\}_{i=1}^{N}$이 있을 때, 이 학습 데이터 셋은 데이터의 모집합 $X$를 어느정도 대체할 수 있다.
위의 두 가정을 통해 우리는 주어진 각 데이터에 대해 동일한 분포로부터 발생한 독립적인 사건의 곱으로 생각할 수 있다.
$$ p^{*}(X) \approx p_{\theta}(X) \approx p_{\theta}(\{x^{(i)}\}_{i=1}^{N}) = p_{\theta}(x^{(1)}, \cdots, x^{(N)}) = p_{\theta}(x^{(1)}) \cdots p_{\theta}(x^{(N)}) = \prod_{i=1}^{N}p_{\theta}(x^{(i)}) $$
2.1) Problem Scenario

$X$ : 연속적인 혹은 이산적인 변수 $x$ N개의 i.i.d sample을 포함하는 데이터 셋
$z$ : 관측되지 않은 continuous random variable
Data $x$ Generation Process
- 1) $z^{(i)}$가 prior $p_{\theta *}(z)$에서 generate
- 2) $x^{(i)}$는 likelihood $p_{\theta *}(x|z)$에서 generate
다만, true(실제) parameter인 $\theta^{*}$와 latent variable $z$을 모르기에 문제가 있다.
여기서 중요한 점은, Posterior $p_{\theta}(z|x)$를 구하기 위해 Marginal Probability $p_{\theta}(x)$를 쉽게 이용할 수 있다는 가정은 하지 않는다.
즉, 아래 2개의 문제들에 대해서도 효율적으로 작동하는 general한 algorithm을 찾아야 한다.
(1) Intractability: Marginal Likelihood $p_{\theta}(x)$를 직접 구하기 어렵다.
- Integration
$p_{\theta}(z)$의 확률분포는 Gaussian Distribution으로 가정하고,
$p_{\theta}(x|z)$을 Decoder의 Neural Network을 통해 구한다 해도,
이를 $\int p_{\theta}(z) p_{\theta}(x|z)dz$ 모든 $z$에 대해 integration을 수행하는 것은 불가능하다.
왜 모든 latent variable $z$에 대해 위의 식을 적분할 수 없을까?
해당 latent variable이 scalar가 아닌 high-dimension vector (possibly correlated)의 경우 vector의 차원이 늘어날수록 complexity가 차원의 지수승으로 늘어나기에 적분식이 너무 복잡해진다.
보다 더 자세한 설명은 아래의 글을 참고하자.

- Bayes' Rule
그렇다면 Posterior Density $p_{\theta}(z|x)$를 구할 수 있냐 싶으면 그것 또한 불가능하다.
$$ p_{\theta}(z|x) = \frac {p_{\theta}(x|z)p_{\theta}(z)} { p_{\theta}(x)} $$
위의 식에서 evidence인 $p_{\theta}(x) $가 intractable 하기 때문이다.
- mean - field VB algorithm
(2) A large dataset : 데이터가 많아 Batch Optimization에서 비용이 많이 든다.
(1) 파라미터 $\theta$에 대한 효과적인 근사치인 MLE 또는 MAP 추정
(2) 관측 값 $x$가 주어졌을 때 잠재 변수 $z$의 효과적인 Posterior 근사치 추정
(3) x의 효율적인 Approximate Marginal Inference
이 상황에서 우리가 찾고자 하는 Marginal $p_{\theta}(x)$를 직접 알아내는 것은 어렵다.
따라서 컨트롤 할 수 있는 Latent Variable z를 활용하여 Marginal $p_{\theta}(x)$에 간접적으로 접근한다.
$$ p_{\theta}(x) = \int p_{\theta}(x,z) dz = \int p_{\theta}(z)p_{\theta}(x|z)dz $$
- $p_{\theta}(z)$ : Prior, 풀고자 하는 문제에 대한 우리의 가정으로 z가 특정 확률 분포를 따를 것이라는 가정을 말한다. 주로 Gaussian 정규 분포로 가정을 진행하며, 이 때 Log를 취하는 것은 데이터를 모델에 넣을 때 불안정한 값을 변환해 주는 것
- $p_{\theta}(x|z)$ : Likelihood, 우리가 만들고자 하는 생성 모델(컨트롤 할 수 있는 z에 의해 데이터가 만들어지기 때문)
Prior $p_{\theta}(z)$는 컨트롤 가능한 확률분포로 설정할 때 편리하기 때문에 VAE 모델은 이를 정규분포로 설정하였고, 이제 Prior를 정하는 문제는 정규분포의 $\mu$와 $\sigma$를 구하는 문제로 변하게 된다.
2.2) The Variational Bound
Marginal Likelihood $\log p_{\theta}(\mathbf{X})$는 Data set $\mathbf{X}$를 구성하고 있는 Data point $x^{(i)}$들의 Marginal Likelihood 들의 합으로 나타낼 수 있다.
$$\log p_{\theta}(x^{(1)}, ... , x^{(N)}) = \sum_{i=1}^{N} \log p_{\theta}(x^{(i)})$$
VAE에서 궁극적으로 원하는 것은 Model을 통해 생성된 이미지가 학습에 사용된 이미지 데이터셋에 대해 가지는 유사도를 가장 높일 수 있는 Model Parameters를 학습하는 것이다.
Model Parameter $\theta$가 주어졌을 때, 우리가 원하는 정답인 $x$가 나올 확률이 가장 높기를 원한다.
$p_{\theta}(x)$가 높을수록 좋은 모델이다.
위에서 언급했듯이, Data likelihood를 Maximize하고 싶기에 $\log p_{\theta}(x^{(i)})$를 최대화시키면 된다.
$z \sim q_{\phi}(z|x^{(i)})$를 따를 때, 즉 Encoder Network를 통해 생성된 latent variable $z$가 Encoder의 Probability Distribution을 따를 때,
앞에서도 언급했지만, Encoder $ q_{\phi}(z|x^{(i)})$를 도입하는 이유는
Data likelihood $p_{\theta}(x)$의 tractable한 lower bound를 유도하여 optimize할 수 있도록 만들기 위해서이다.
Data likelihood $\log p_{\theta}(x^{(i)})$에 관한 식을 다음과 같이 작성할 수 있다.

$$ \log p_\theta(x^{(i)}) = \mathbb{E} _{z \sim q _{\phi}(z|x^{(i)})} [\log p_\theta(x^{(i)})] \: (p_\theta(x^{(i)})\: \text{Does not depend on} \: z) $$
직관적으로는:
$p_\theta(x^{(i)})$는 $x^{(i)}$에 대해서만 dependent하지, $z$에 대해 independent한 constant이다.
즉 constant에 대한 Expectation은 constant 그 자체이므로 $E[c] = c$ 와 같이 식 전개가 가능하다.
수식적으로는:
$$\mathbb{E} _{z \sim q _{\phi}(z|x^{(i)})} [\log p_\theta(x^{(i)})] = \int p_\theta(x^{(i)}) q _{\phi}(z|x^{(i)}) dz = \int p_\theta(x^{(i)}) \frac { q _{\phi}(z, x^{(i)})} { q _{\phi}(x^{(i)})} dz$$
$$= \frac {p_\theta(x^{(i)})} { q _{\phi}(x^{(i)})} \int q _{\phi}(z, x^{(i)}) dz = \frac {p_\theta(x^{(i)})} {q _{\phi}(x^{(i)})} q _{\phi}(x^{(i)}) = p_\theta(x^{(i)})$$
$$= \mathbb{E} _z \left[\log \frac{p_\theta(x^{(i)}|z)p_\theta(z)}{p_\theta(z|x^{(i)})}\right] \: \text{(Bayes' Rule)}$$
$$= \mathbb{E}_z \left[\log \frac{p_\theta(x^{(i)}|z)p_\theta(z)}{p_\theta(z|x^{(i)})} \frac{q_\phi(z|x^{(i)})}{q_\phi(z|x^{(i)})}\right] \: \text{(Multiply by constant)}$$
이때, KLD의 특성에 의해 $z$가 따르고 있는 Distribution과 $\log$의 분자에 있는 항이 동일할 경우 Expectation 식을 KLD로 변형할 수 있다.
따라서 Expectation 안의 $\log$항 분자에 $q_\phi(z|x^{(i)})$를 올린다.
$$= \mathbb{E}_z[\log p_\theta(x^{(i)}|z)] - \mathbb{E}_z \left[\log \frac{q_\phi(z|x^{(i)})}{p_\theta(z)}\right] + \mathbb{E}_z \left[\log \frac{q_\phi(z|x^{(i)})}{p_\theta(z|x^{(i)})}\right] \: \text{(Logarithms)}$$
$$= \mathbb{E}_z[\log p_\theta(x^{(i)}|z)] - D_{KL}(q_\phi(z|x^{(i)}) \parallel p_\theta(z)) + D_{KL}(q_\phi(z|x^{(i)}) \parallel p_\theta(z|x^{(i)}))$$
KLD에 의해 $z$가 Continuous Variable일 경우 다음과 같이 정리가능하다.
$$ \mathbb{E}_{z \sim q_\phi(z|x^{(i)})} \left[\log \frac{q_\phi(z|x^{(i)})}{p_\theta(z)}\right] = \int_z \log \frac{q_\phi(z|x^{(i)})}{p_\theta(z)} q_\phi(z|x^{(i)}) dz$$
$$KL(P\parallel Q) = \sum_x P(x) \log \frac{P(x)}{Q(x)}$$
Kullback - Lively Divergence (KLD)
$$D_{KL} (p \parallel q) = \sum_{x} p(x) \log\left(\frac{p(x)}{q(x)}\right) = \mathbb{E}_{x \sim p} \left[ \log\left(\frac{p(x)}{q(x)}\right) \right]$$
- 모델로 만든 분포 q와 실제 분포 p 사이에서 분포간의 차이를 나타낼 때 사용
- x가 실제 분포 P를 따른다: $x \sim p$
- $KL(p \parallel q) \geq 0$
- $KL(p \parallel q) \neq KL(q \parallel p)$: KLD는 거리 개념이 아니다
Expectation of Random Variable g(X)
$$E \left[ g(X) \right] = \sum g(x) P_{X}(x)$$
- $\sum (\text{변수 그대로} \times \: \text{ Main 확률})$
- 변수는 합성 form 그대로
- 확률은 Main(원본) 변수의 확률

최종적으로 식을 정리하면 다음과 같다.
$$\log p_\theta(x^{(i)}) = \mathbb{E}_z[\log p_\theta(x^{(i)}|z)] - D_{KL}(q_\phi(z|x^{(i)}) \parallel p_\theta(z)) + D_{KL}(q_\phi(z|x^{(i)}) \parallel p_\theta(z|x^{(i)}))$$
- $\mathbb{E}_z[\log p_\theta(x^{(i)}|z)]$: Decoder에 의해 잘 복원되도록 하는 Term
- $ - D_{KL}(q_\phi(z|x^{(i)}) \parallel p_\theta(z))$: Encoder를 통과한 Latent Variable의 Distribution이 Prior Gaussian Distribution과 비슷해지도록 학습
- $D_{KL}(q_\phi(z|x^{(i)}) \parallel p_\theta(z|x^{(i)}))$: Encoder를 통해 나온 확률분포가 intractable한 $ p_\theta(z|x^{(i)})$와 비슷해지도록 학습
따라서, KLD의 성질에 의해
$ D_{KL}(q_\phi(z|x^{(i)}) \parallel p_\theta(z|x^{(i)})) \geq 0 $이므로
intractable한 위의 항은 Control할 수 없고, 나머지 Term은 Control할 수 있으므로
$$\mathcal{L}(x^{(i)}, \theta, \phi) = \mathbb{E}_z[\log p_\theta(x^{(i)}|z)] - D_{KL}(q_\phi(z|x^{(i)}) \parallel p_\theta(z)) $$
$\mathcal{L}(x^{(i)}, \theta, \phi) $를 Maximize 시키는 것을 목표로 한다.
$\mathcal{L}(x^{(i)}, \theta, \phi) $을 구성하는 $\log p_\theta(x^{(i)}|z)$과 $D_{KL}(q_\phi(z|x^{(i)}) \parallel p_\theta(z))$ 모두 Differentiable하므로 Gradient 값을 계산해서 최적화할 수 있다.

따라서 다음의 식이 성립한다.
$$\log p_\theta(x^{(i)}) = \mathcal{L}(x^{(i)}, \theta, \phi) + D_{KL}(q_\phi(z|x^{(i)}) \parallel p_\theta(z|x^{(i)})) \geq \mathcal{L}(x^{(i)}, \theta, \phi)$$
이므로 $\mathcal{L}(x^{(i)}, \theta, \phi)$을 Evidence Lower BOund (ELBO)이라 하며, Training을 통해 $\mathcal{L}(x^{(i)}, \theta, \phi)$를 Maximize 하는 parameter $\theta^*, \phi^*$를 찾으면 된다.
$$\theta^*, \phi^* = \arg \max_{\theta,\phi} \sum_{i=1}^N \mathcal{L}(x^{(i)}, \theta, \phi)$$
- $\theta$: Decoder의 Parameter
- $\phi$: Encoder의 Parameter
그렇다면 반드시 EBLO $\mathcal{L}(x^{(i)}, \theta, \phi)$를 Maximize하는 것이 $\log p_\theta(x^{(i)})$의 Maximization을 보장하는가?
즉, intractable한 $D_{KL}(q_\phi(z|x^{(i)}) \parallel p_\theta(z|x^{(i)})) \geq 0$이기는 하나, $\mathcal{L}(x^{(i)}, \theta, \phi)$가 증가하면서 $D_{KL}(q_\phi(z|x^{(i)}) \parallel p_\theta(z|x^{(i)})) \geq 0$ 항이 양수이지만 감소한다면
이는 optimal한 maximum $\mathcal{L}(x^{(i)}, \theta, \phi)$를 보장하지는 못하지 않는가?
이에 대한 대답은 EBLO를 Maximize하는 것이기 때문에 EBLO에 대한 식으로 변형해서 봐야 한다.
$$ \mathcal{L}(x^{(i)}, \theta, \phi) = \log p_\theta(x^{(i)}) - D_{KL}(q_\phi(z|x^{(i)}) \parallel p_\theta(z|x^{(i)}))$$
$ \mathcal{L}(x^{(i)}, \theta, \phi)$의 Maximization은 결국 parameter $\phi, \theta$ 2개를 optimize 하면서 우리가 고려하는 2개의 목적을 달성한다.
- 1) $ p_\theta(x^{(i)})$를 approximately maximize 시키면서, Generative Model의 성능을 향상시킨다.
- 2) $D_{KL}(q_\phi(z|x^{(i)}) \parallel p_\theta(z|x^{(i)}))$를 minimize 시키면서, Encoder $q_\phi(z|x^{(i)})$가 true posterior $p_\theta(z|x^{(i)})$로 더 잘 approximate 시킬 수 있도록 한다. (KL = 0이면 marginal likelihood를 direct하게 optimize할 수 있으므로 결과적으로는 이득)
즉, 결론은 다음과 같다:
1. $q_\phi$가 충분히 flexible해서 Optimum에 도달했을 때, $q_\phi(z|x^{(i)}) = p_\theta(z|x^{(i)})$가 되어, Marginal Likelihood $p_\theta(x^{(i)})$가 ELBO가 된다. (how EM works) $\log p_\theta(x^{(i)}) = \mathcal{L}(x^{(i)}, \theta, \phi)$이므로 optimization step이 $p_\theta(x^{(i)})$의 maximize를 보장한다.
2. $q_\phi(z|x^{(i)})$를 true posterior $p_\theta(z|x^{(i)})$로 optimize할 수 없을 때는, ELBO를 maximize시키는 건 Maringal Likelihood $p_\theta(x^{(i)})$를 maximize하거나, KL Divergence $D_{KL}(q_\phi(z|x^{(i)}) \parallel p_\theta(z|x^{(i)}))$를 minimize 시킨다.
그런데 둘 중 무엇을 하더라도 결국 2개의 목적 중 하나를 달성하기 때문에 각 step에서 $q_\phi(z|x^{(i)})$ true posterior가 Maximize가 되지 않을 수는 있으나,
결과적으로는, KL Divergence가 Minimize되도록 update를 하고 나면 $q_\phi(z|x^{(i)}) \approx p_\theta(z|x^{(i)})$가 되어
$D_{KL} \approx 0$이 되고, marginal likelihood $p_\theta(z|x^{(i)})$를 direct하게 optimize할 수 있게 된다.

그런데 일반적으로 Minimization을 수행하므로, 위의 Term에 $-$를 붙여서 Maximize가 아닌 Minimize 시킨다.
$$\arg \min_{\theta,\phi} \sum_{i=1}^N - \mathcal{L}(x^{(i)}, \theta, \phi)$$
$$= \arg \min_{\theta,\phi} \sum_i -\mathbb{E}_{q_\phi(z|x_i)}[\log(p(x_i|g_\theta(z)))] + D_{KL} (q_\phi(z|x_i)||p(z))$$
따라서 Minimize 시키는 항 안의 2개의 Term을 각각 Reconstruction Error, Regularization이라 한다.
- Reconstruction Error: $-\mathbb{E}_{q_\phi(z|x_i)}[\log(p(x_i|g_\theta(z)))] $
- Regularization: $KL(q_\phi(z|x_i)||p(z))$
- 가정한 $p(z)$와의 Distribution 차이를 KLD를 최소화시킴으로써 줄인다.
$\mathbb{E}_{z \sim q_{\phi}(z|x)} \left[ \log p_{\theta}(x|z) \right]$ 최대화
이 항은 latent variable로 복구된 결과 $x$에 대한 기대값으로, 다른 말로 reconstruction term이라 한다.
ELBO가 최대화되려면 reconstruction term으로 복구된 결과의 기대값이 높아야 한다
$$\arg \min_{\theta,\phi} \sum_i -\mathbb{E}_{q_\phi(z|x_i)}[\log(p(x_i|g_\theta(z)))] + KL(q_\phi(z|x_i)||p(z))$$
위의 식에서 Reconstruction Error Term을 살펴보자.
$$\mathbb{E}_{q_\phi(z|x_i)}[\log(p_\theta(x_i|z))] = \int \log(p_\theta(x_i|z))q_\phi(z|x_i)dz$$
reconstruction term은 Expectation 형태로 되어있기 때문에 적분 형태로 바꿔줄 수 있지만, z에 대한 적분은 계산하기 쉽지 않다.
따라서 이때 Monte-Carlo Technique을 사용한다. 어떤 분포를 가정하고 그 분포에서 무한개 혹은 굉장히 큰 수의 sampling을 해서 평균을 내면 그것이 실제 true 기댓값과 거의 동일해질 것이라는 가정이다.
$$\approx \frac{1}{L}\sum_{z^{i,l}} \log(p_\theta(x_i|z^{i,l}))$$
어떠한 분포를 가정하고, 해당 분포에서 Sampling을 하는데 굉장히 큰 수에 대해 Sampling을 한 후에 평균을 내면 전체에 대한 Expectation과 어느정도 비슷해진다.

다만, DL에서 Monte-Carlo Technique를 사용하기 힘든 이유는 계속해서 Sampling을 하면 계산량이 과도하게 많아지기 때문이다.
따라서, VAE의 저자들은 다음과 같은 Trick을 사용했다:
- $L$: Latent Vector의 Sample 개수
- $L = 1$을 편의를 위해 설정한다. (Sample 개수가 하나)
즉, $z$에 대한 Integration이 힘들기에 이를 대신하고자 Monte-Carlo 방법을 사용하여 수없이 많이 Sampling을 해서 이를 평균내고자 했으나,
그냥 Random하게 하나의 Sample만을 Sampling하고 이를 대표값으로 설정한 것이다.
$$\mathbb{E}_{q_\phi(z|x_i)}[\log(p_\theta(x_i|z))] = \int \log(p_\theta(x_i|z))q_\phi(z|x_i)dz$$
$$ \approx \frac{1}{L}\sum_{z^{i,l}} \log(p_\theta(x_i|z^{i,l})) \approx \log(p_\theta(x_i|z^i))$$
지금까지 Monte-Carlo Technique를 사용해서 위와 같이 변형할 수 있었다.

1) Decoder의 Output인 확률분포가 Bernoulli Distribution을 따른다고 가정했기에 다음과 같이 식을 작성할 수 있다.
$$\log(p_\theta(x_i|z^i)) = \log\prod_{j=1}^D p_\theta(x_{i,j}|z^i) = \sum_{j=1}^D \log p_\theta(x_{i,j}|z^i)$$
$$= \sum_{j=1}^D \log p_{i,j}^{x_{i,j}}(1-p_{i,j})^{1-x_{i,j}}$$
$$= \sum_{j=1}^D x_{i,j}\log p_{i,j} + (1-x_{i,j})\log(1-p_{i,j})$$
결론적으로 $\log (p_{\theta}(x_i|z^i))$은 Cross-Entropy 식 형태로 쓸 수 있다.

2) Decoder의 Output인 확률분포가 Gaussian Distribution을 따른다면 다음과 같이 식을 작성할 수 있다.
- Decoder가 Gaussian Distribution을 따를 때:
$$\log(p_\theta(x_i|z^i)) = \log(\mathcal{N}(x_i; \mu_i, \sigma_i^2 I))$$
$$ = - \sum_{j=1}^D \frac{1}{2}\log(\sigma_{i,j}^2) + \frac{(x_{i,j} - \mu_{i,j})^2}{2\sigma_{i,j}^2}$$
- Decoder가 Gaussian Distribution w/ identity covariance를 따를 때:
$$\log(p_\theta(x_i|z^i)) \propto - \sum_{j=1}^D (x_{i,j} - \mu_{i,j})^2$$
Decoder - Bernoulli Distribution: CEE
Decoder - Gaussian Distribution: MSE
$- D_{\textrm{KL}}(q_{\phi}(z|x) || \log p_{\theta}(z))$ 최대화
이 항은 인코더 네트워크가 만들어낸 latent variable $z$의 확률분포와 우리가 원했던 latent variable $z$의 확률분포 사이의 연관성을 설명한다.
당연히 그 연관성이 높아야 하므로 $D_{\textrm{KL}}$은 최소로 되어야 하고, $-D_{\textrm{KL}}$는 최대화 되어야 할 것이다. 이 항을 다른 말로 regularization term이라 한다.
※ Regularization의 효과
1. Continuity
: 비슷한 성질을 가진 데이터들이 비슷한 위치의 Latent Space에 매핑되어 가까이 위치한 z에서 만들어지는 Sample끼리 서로 비슷하기를 기대
2. Completeness
: Latent Space에서 Sampling되어지는 z는 유의미한 정보를 포함하고 있어야 함
Regularization Term: 은 아래의 2개의 가정을 따른다
- Encoder를 통과한 Distribution이 아래의 Gaussian Distribution을 따라야 한다.
- Multivariate Gaussian Distribution with diagonal covariance
$$q_{\phi}(z|x_i) \sim N(\mu_i, \sigma_{i}^{2} I)$$
- Prior Distribution에 해당하는 $p(z)$가 $N(0, I)$를 따른다고 가정한다.
- 평균이 0이고, Covariance Matrix가 Identity Matrix인 Multivariate Normal Distribution을 따른다.
$$p(z) \sim N(0, I)$$

$$\arg \min_{\theta,\phi} \sum_i -\mathbb{E}_{q_\phi (z|x_i)}[\log(p(x_i|g_\theta(z)))] + KL(q_\phi(z|x_i)||p(z))$$
위의 전체 ELBO식에서 Regularization Term을 관찰하면,
$$KL(q_\phi(z|x_i) \parallel p(z)) = \frac{1}{2} \left(\text{tr}(\sigma_{i}^{2}I) + \mu_{i}^{T}\mu_{i} - J + \ln \frac{1}{\prod_{j=1}^{J} \sigma_{i,j}^{2}} \right)$$
$$= \frac{1}{2}\left(\sum_{j=1}^J \sigma_{i,j}^2 + \sum_{j=1}^J \mu_{i,j}^2 - J - \sum_{j=1}^J \ln(\sigma_{i,j}^2)\right)$$
$$= \frac{1}{2}\sum_{j=1}^J (\mu_{i,j}^2 + \sigma_{i,j}^2 - \ln(\sigma_{i,j}^2) - 1)$$
여기서 $\text{tr}$는 trace라고 대각행렬의 대각선 성분의 합을 의미한다.
KLD for multivariate normal distributions
$$D_{KL}(\mathcal{N}_0||\mathcal{N}_1)$$
$$ = \frac{1}{2}\left(tr(\Sigma_1^{-1}\Sigma_0) + (\mu_1 - \mu_0)^T\Sigma_1^{-1}(\mu_1 - \mu_0) - k + \ln\left(\frac{\det \Sigma_1}{\det \Sigma_0}\right)\right)$$
- $\mathcal{N}_0$: $N(\mu_i, \sigma_{i}^{2} I)$
- $\mathcal{N}_1$: $N(0, I)$
따라서 Regularization Term은 다음과 같이 계산된다.
$$KL(q_\phi(z|x_i) \parallel p(z)) = \frac{1}{2}\sum_{j=1}^J (\mu_{i,j}^2 + \sigma_{i,j}^2 - \ln(\sigma_{i,j}^2) - 1)$$
2.3) The SGVB estimator and AEVB algorithm

- 최적화 하고 싶은 Lower Bound와 미분 값에 Estimator를 적용
- Gradient Based Optimization이 가능
2.4) The reparameterization trick
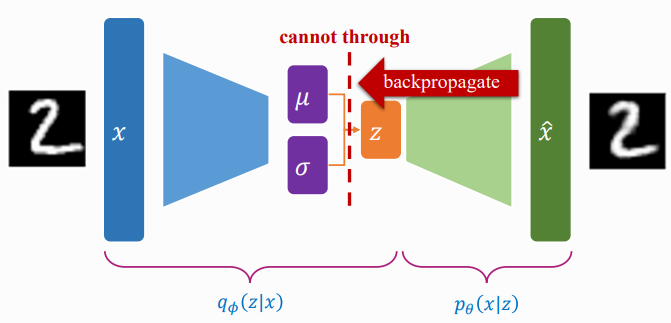
- Before Reparameterization: Backpropagation X
$$z^{i,l} \sim \mathcal{N}(\mu_i, \sigma_i^2 I) $$
$z$를 직접 Sampling 할 경우 Random 연산은 미분이 불가능하기 때문에 역전파가 불가능하다.
- After Reparameterization: Backpropagation O
$$z^{i,l} = \mu_i + \sigma_i \odot \epsilon$$
따라서 Reparameterization trick을 사용하는데,
이는 z를 $N(\mu, \sigma)$에서 직접적으로 Sampling하지 않고 Deterministic output vector + Gaussian Noise로 계산하여 Stochastic Node와 Deterministic Node로 분리하는 것이다.

Encoder를 통해 바로 Gaussian Distribution을 만든 후에 Sampling하는 것보다는
Standard Gaussian Distribution에서 $\varepsilon$을 Sampling을 한 후 이를 실제 $\sigma_i$에 곱해준 후에 $\mu_i$를 더해주는 방식으로 Backpropagation을 가능하게 만들어주면서,
실제 Sampling을 한 것 같은 효과를 줄 수 있다.
$z^{i, l}$에 대한 식이 나온다는 점에서 미분가능한 식이 되어 Backpropagation이 가능하게 된다.
Reparameterization Trick을 통해 random variable $z$를 deterministic variable $z$로 표현하게 되는 것이다.
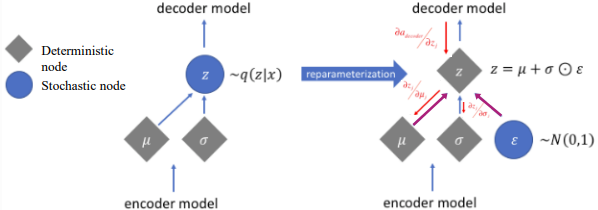
Reparameterization Trick을 하는 이유가 Gradient 계산 시 Random한 Stochastic Node로 인해 Gradient가 결정되지 않아(Randomness) Deterministic Node로 바꾸어주는 것인데,
그렇다면 $\varepsilon$도 Random이라 Backpropagation이 안되지 않는가?
문제 없다. 어차피 Stochastic Node의 경우 Gradient 계산시 Differentiation을 수행하는 변수가 분모에만 들어가지 않는다면 Gradient가 유일하게 결정된다. (이미 Sampling을 하면 Value가 결정되므로)
즉, Stochastic한 Random Value를 가지는 변수가 Gradient의 분모에 들어간다면 Randomness로 인해 Gradient가 결정되지 않아 Backpropagation이 안되지만, 반대로 분모에만 들어가지 않는다면 문제 없다.
논문에서는 몇가지 Reparametrization Function에 대한 팁을 제공한다.
어떠한 $q_\phi (z|x)$에 대하여 differentiable transformation $g_\phi(.)$와 auxiliary variable $\varepsilon \sim p(\varepsilon)$을 선택해야 하는가?
(1) $g_\phi(\varepsilon, x)$를 $q_\phi (z|x)$의 Inverse CDF로 정의한 뒤, $\epsilon$을 Uniform(0,1) 균등 분포에서 Sampling하여 계산
(2) Gaussian과 유사한 경우 Location-scale을 설정하여 Location + scale*epsilon으로 정하고, epsilon을 정규분포(0,1)에서 sampling하여 계산
(3) 다른 보조 변수들의 변환으로 계산
3) Example: Variational Auto-Encoder
Neural Network를 Probabilistic Encoder $q_\phi(z|x)$로 사용하고,
parameter $\phi, \theta$들이 AEVB Algorithm에 의해 optimize 될 때,
본 논문에서 제안하는 내용이 variational auto-encoder가 된다.
- Prior $p_\theta(z)$: Centered Isotropic Multivariate Gaussian ($p_\theta(z) = \mathcal(N)(z; 0, I)$, No parameters)
- Likelihood $p_\theta(x|z)$: Multivariate Gaussian (real-valued) or Bernoulli (binary)
- $z$로부터 single MLP Layer를 거쳐 distribution parameter를 compute한다
그리고 true (but intractable) posterior $p_\theta(z|x)$를 approximate Gaussian form with an approximately diagonal covariance의 형태로 가정한다.
즉, 이러한 경우에는 variational approximate posterior $q_\phi(z|x)$를 multivariate gaussian with a diagonal covariance structure로 세팅할 수 있다.
$$\log q_{\phi} (z | x^{(i)}) = \log\mathcal{N}(z; \mu^{(i)}, \sigma^{2(i)}\mathbf{I})$$
그리고 이제 앞의 Reparameterization Trick을 이용하여 이 $z^{(i,l)} \sim q_\phi(z|\mathbf{x}^{(i)})$ posterior에서의 sampling을 간접적으로 할 수 있다.
$$z^{(i,l)} = g_\phi(\mathbf{x}^{(i)}, \epsilon^{(l)}) = \mu^{(i)} + \sigma^{(i)} \odot \epsilon^{(l)} \: \text{where} \: \epsilon^{(l)} \sim \mathcal{N}(0,\mathbf{I})$$
$\odot $은 element-wise product 이다.
그리고 posterior $q_\phi(z|x)$와 prior $p_\theta (z)$모두 Gaussian 이므로 아래와 같이 근사할 수 있다.
이제 다음의 ELBO 수식의
$$\mathcal{L}(\theta, \phi, x^{(i)}) \simeq -D_{\mathrm{KL}}(q_{\phi}(z|x^{(i)}) || p_{\theta}(z)) + \mathbb{E}_{q_{\phi}(z|x^{(i)})}[\log p_{\theta}(x^{(i)}|z)]$$
우항 첫번째 term은 다음과 같이 쓸 수 있다.
$$ -D_{\mathrm{KL}}(q_{\phi}(z|x^{(i)}) || p_{\theta}(z)) = \frac{1}{2} \sum_{j=1}^{J} \left( 1 + \log((\sigma_{j}^{(i)})^2)) - (\mu_j^{(i)})^2 - (\sigma_j^{(i)})^2 \right) $$
여기서 $J$는 latent space의 dimension을 나타낸다. 우항 두번째 term은 Monte Carlo estimation으로 다음과 같이 쓸 수 있다.
$$\mathbb{E}_{q_{\phi}(z|x^{(i)})}[\log p_{\theta}(x^{(i)}|z)] = \frac{1}{L}\sum_{l=1}^{L} \log p_{\theta}(x^{(i)}|z^{(i,l)})$$
여기서 $L$은 몬테카를로 샘플 개수를 나타낸다. 따라서, ELBO 수식은 다음과 같이 근사될 수 있다.
$$\mathcal{L}(\theta, \phi, x^{(i)}) \simeq \frac{1}{2} \sum_{j=1}^{J} \left( 1 + \log((\sigma_{j}^{(i)})^2)) - (\mu_j^{(i)})^2 - (\sigma_j^{(i)})^2 \right) + \frac{1}{L}\sum_{l=1}^{L} \log p_{\theta}(x^{(i)}|z^{(i,l)})$$
4) VAE Structure
- Encoder $q_{\phi}$: Gaussian Encoder $\mu_i, \sigma_i$
- Decoder $g_{\theta}$: Bernoulli Decoder $p_i$

- Reconstruction Error: Decoder Output $p_i$가 Bernoulli Distribution을 따르므로 Cross-Entropy Loss식이 된다.
- Regularization Error: KL Divergence를 사용하므로 위와 같은 식이 나온다.
아래와 같이 Decoder의 Output이 따르는 확률분포를 Gaussian Distribution으로 가정한다면 다른 Case도 가능하다.

Encoder는 Gaussian Encoder로 고정시키고, Decoder의 Distribution만 변화시키면 된다.
- Gaussian Decoder
- Gaussian Decoder w/ Identity Covariance
5) VAE Characteristics
Latent Space를 늘릴수록 복원이 더 잘되는 경향이 있으나, Latent Space 자체는 Input Space의 차원을 압축하기 위해 도입됐으므로 과도하게 늘리면 Latent Space를 도입하는 의미가 없다.

VAE의 특징들을 정리해보면 다음과 같다:
1) Decoder가 최소한 학습 데이터는 생성해낼 수 있게 된다.
- Generated Data는 Input Data과 조금 닮아 있다.
- 즉, 아주 새로운 Data를 생성해내지는 못한다.
2) Encoder가 최소한 학습 데이터는 잘 Latent Vector로 표현할 수 있게 된다.
- Data의 추상화(차원 축소)를 위해 많이 사용된다.


![[Paper Review] Image Super-Resolution via Iterative Refinement (SR3)](/content/images/size/w960/2024/09/-----2024-09-10-203649.png)
![[Paper Review] Diffusion Models Beat GANs on Image Synthesis](/content/images/size/w960/2024/07/Screenshot-2024-08-01-at-05.49.39.png)
![[Paper Review] CTAB-GAN: Effective Table Data Synthesizing](/content/images/size/w960/2024/07/Screenshot-2024-07-28-at-07.39.16.png)
![[Paper Review] Denoising Diffusion Implicit Models (DDIM)](/content/images/size/w960/2024/07/-----2024-07-24-174331.png)